
Ever wondered why 87% of machine learning projects never reach production? The answer often lies in the gap between developing models and deploying them effectively. MLOps best practices bridge this critical gap.
Machine Learning Operations (MLOps) combines ML system development with operations, creating a systematic approach to deploy, monitor, and maintain ML models in production environments. Think of MLOps as the backbone that transforms your experimental models into reliable, scalable business solutions. Without proper MLOps best practices, even the most sophisticated algorithms can fail spectacularly in real-world scenarios.
This guide delivers actionable MLOps best practices that data scientists, ML engineers, and DevOps teams can implement immediately. You’ll discover how to build robust ML pipelines, ensure model reliability, and scale your machine learning operations effectively.
Breaking Down the MLOps Lifecycle
Building and maintaining machine learning models isn’t a one-time task, but it’s a continuous, evolving process. The MLOps lifecycle brings structure and accountability to this journey, ensuring each phase, from data preparation to model retraining, is efficient, trackable, and production-ready.
By breaking the workflow into well-defined stages, teams can reduce friction between development and operations, improve collaboration, and scale ML systems with confidence. Below is a breakdown of the key phases that make up the modern ML lifecycle.
Overview of the ML Lifecycle
The ML lifecycle encompasses six critical phases that transform raw data into production-ready models:
- Data Collection & Preparation: Teams gather, clean, and prepare datasets for model training. This phase often consumes 80% of project time, making efficient data handling crucial for success.
- Model Development: Data scientists experiment with algorithms, feature engineering, and hyperparameter tuning. This iterative process requires systematic tracking and version control to ensure consistency and accuracy.
- Model Validation: Teams evaluate model performance using various metrics and validation techniques to ensure its accuracy and reliability. Proper validation prevents overfitting and ensures model generalization.
- Deployment: Models transition from development environments to production systems. This phase requires careful orchestration and infrastructure management.
- Monitoring & Retraining: Continuous monitoring detects model drift and performance degradation. Teams must implement automated retraining pipelines to maintain model accuracy and reliability.
How MLOps Integrates DevOps Principles into the ML Lifecycle?
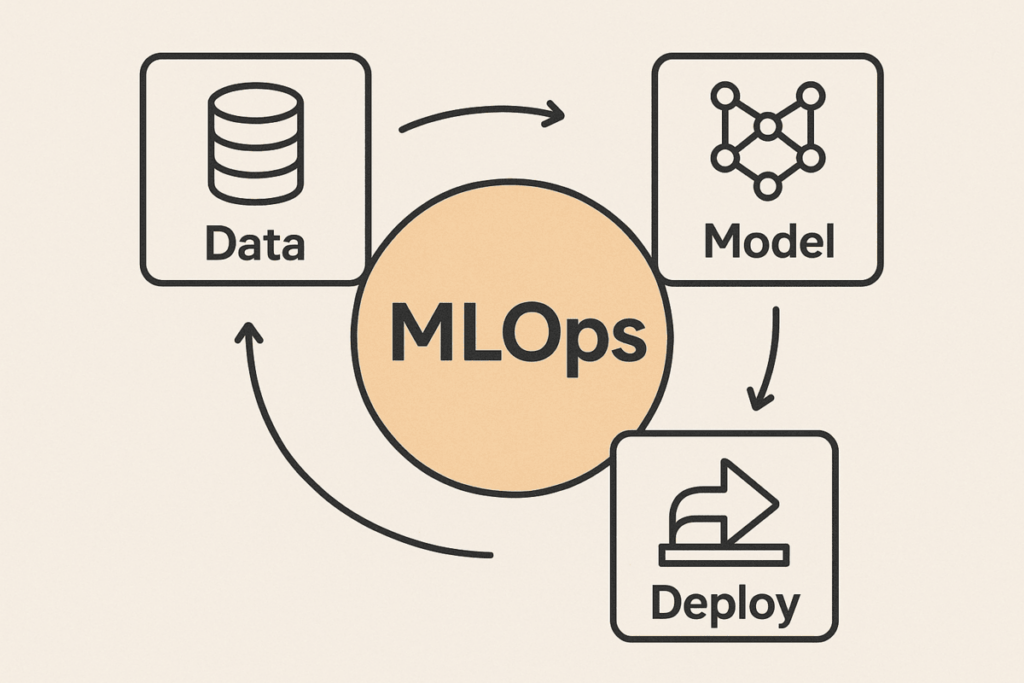
MLOps applies proven DevOps methodologies to machine learning workflows. Just as DevOps revolutionized software development, MLOps best practices transform how teams build and deploy ML systems.
Companies implementing comprehensive MLOps best practices report 60% faster model deployment and 40% reduction in production incidents. The integration focuses on three core principles:
- Continuous Integration: Every code change triggers automated testing and validation. This ensures model consistency and prevents regression issues.
- Continuous Deployment: Automated pipelines deploy validated models to production environments, ensuring seamless integration and deployment. This reduces manual errors and accelerates time-to-market.
- Continuous Monitoring: Real-time tracking identifies issues before they impact business operations. Incorporating DevOps monitoring strategies into ML workflows helps teams proactively detect anomalies, track model performance, and uphold system reliability.
Proven Best Practices for a Scalable and Reliable MLOps Workflow
Implementing machine learning at scale requires more than just building good models—it demands a disciplined, repeatable approach to collaboration, deployment, and ongoing management. That’s where MLOps best practices come in.
These guidelines help teams align workflows, reduce deployment bottlenecks, improve model performance monitoring, and strengthen governance. Whether you’re just starting with MLOps or looking to optimize existing pipelines, following proven practices ensures your models stay accurate, secure, and production-ready over time.
This is especially important for organizations undergoing digital transformation or adopting cloud migration solutions, where consistent version control and deployment reliability are essential.

1. Version Control Everything
Implement comprehensive version control for all ML artifacts, including code, data, models, and configurations. Version control creates reproducible ML workflows. When models fail in production, teams can quickly identify the changes and roll back to a stable version.
How to Apply:
- Use Git for source code management with clear branching strategies
- Implement data versioning using tools like DVC or Pachyderm
- Version model artifacts with unique identifiers and metadata
- Track configuration changes across environments
- Maintain audit trails for compliance and debugging
2. Automate the ML Pipeline
Develop automated MLOps pipeline best practices that encompass the entire ML workflow, from data ingestion to model deployment and beyond. Automation eliminates manual bottlenecks and ensures consistent model quality. Teams that use automated MLOps pipeline best practices deploy models five times faster than those using manual processes.
Incorporating DevOps best practices—such as continuous integration, delivery automation, and environment consistency—further enhances the scalability and reliability of ML operations.
How to Apply:
- Create automated data validation and preprocessing pipelines
- Implement continuous training workflows triggered by data changes
- Automate model testing and validation procedures
- Set up automated deployment pipelines with rollback capabilities
- Schedule periodic retraining based on performance metrics
3. Monitor Models in Production
Implement comprehensive monitoring systems that track model performance, data drift, and system health to ensure optimal performance. Production monitoring prevents silent model failures. Early detection of issues allows teams to maintain service quality and user trust.
In cases where models are deployed as part of a broader cloud migration assessment, it’s especially critical to monitor system behavior in real time to validate migration success and ensure continuity.
How to Apply:
- Set up real-time performance monitoring dashboards
- Implement data drift detection algorithms
- Monitor prediction accuracy and business metrics
- Create alerting systems for anomalies and threshold breaches
- Track resource utilization and system performance
4. Ensure Data Quality and Integrity
Implement robust data validation and quality assurance processes throughout the ML pipeline. Poor data quality causes 60% of ML project failures. Implementing strong data quality measures ensures reliable model performance.
How to Apply:
- Create automated data validation rules and checks
- Implement data lineage tracking and documentation
- Monitor data freshness and completeness
- Establish data governance policies and procedures
- Regular data quality audits and reporting
5. Use Modular and Scalable Architecture
Design ML systems using modular, microservices-based architectures that support independent scaling and deployment. This approach enhances cloud scalability, enabling teams to handle growing workloads efficiently and update individual components without disrupting the entire system. It also reduces deployment risks and improves system maintainability.
How to Apply:
- Break down ML pipelines into independent, reusable components
- Implement containerization using Docker and orchestration with Kubernetes
- Design APIs for model serving and integration
- Create horizontal scaling strategies for high-throughput scenarios
- Implement load balancing and traffic management
6. Implement Robust Security & Governance
Establish comprehensive MLOps security best practices that protect sensitive data and ensure regulatory compliance. Security breaches in ML systems can expose sensitive training data and compromise model integrity. Robust MLOps security best practices, supported by modern cloud security tools, help safeguard both data and intellectual property across cloud-based ML environments.
How to Apply:
- Implement encryption for data at rest and in transit
- Establish access controls and authentication mechanisms
- Create audit trails for all ML operations
- Implement model explainability and fairness checks
- Regular security assessments and penetration testing
7. Enable Collaboration Between Teams
Foster collaboration between data scientists, ML engineers, DevOps teams, and business stakeholders through shared tools and processes. Effective collaboration reduces silos and accelerates project delivery. Teams with strong collaboration practices complete ML projects 40% faster than isolated teams.
How to Apply:
- Implement shared experiment tracking and model registry
- Create cross-functional documentation and knowledge sharing
- Establish regular review and feedback cycles
- Use collaborative development environments
- Implement clear communication protocols and escalation procedures
8. Continuous Integration and Continuous Deployment
Implement CI/CD pipelines specifically designed for ML workflows, including automated testing and validation. CI/CD for ML requires specialized approaches that account for model training, validation, and deployment complexities. Proper implementation ensures reliable and safe model deployments.
Many teams use cloud implementation services to integrate CI/CD seamlessly into their ML infrastructure, ensuring flexibility, scalability, and resilience.
How to Apply:
- Create automated testing suites for ML code and models
- Implement staged deployment strategies (canary, blue-green)
- Set up automated rollback mechanisms for failed deployments
- Integrate model validation into the CI/CD pipeline
- Implement feature flags for gradual feature rollouts

Common MLOps Pitfalls and How to Avoid Them
Even the most promising machine learning projects can fail without the right operational strategy in place. From unmanaged data pipelines to inadequate model monitoring, common MLOps mistakes often result in delays, degraded performance, and wasted resources.
Recognizing these pitfalls early is crucial to building scalable and resilient ML systems. Many organizations rely on expert MLOps services to proactively address these issues and establish robust workflows.
Below are some of the most frequent challenges teams face, along with practical ways to avoid them, so you can streamline collaboration, maintain model integrity, and drive long-term value from your MLOps investments. As organizations undergo DevOps transformation, many of these issues become more manageable through shared practices and automation frameworks.
1. Models as Code
Many teams treat models as black boxes, rather than applying software engineering principles. This approach creates maintenance nightmares and deployment challenges.
How to Avoid?
Treat models as code with proper version control, testing, and documentation. Implement code review processes for model changes.
2. No Monitoring
Deploying models without monitoring creates blind spots that lead to silent failures and degraded performance.
How to Avoid?
Implement comprehensive monitoring from day one. Track both technical metrics and business KPIs to ensure model effectiveness.
3. Poor Reproducibility
Inconsistent environments and undocumented dependencies make it impossible to reproduce model results or debug issues.
How to Avoid?
Use containerization and infrastructure as code. Document all dependencies and maintain consistent environments across development and production.
4. Data & Bias Issues
Ignoring data quality and bias leads to unreliable models that perform poorly on real-world data.
How to Avoid?
Implement rigorous data validation and bias detection. Regular audits ensure model fairness and accuracy.
Tools & Frameworks That Support MLOps
Effective MLOps depends heavily on the right combination of tools and frameworks that support every phase of the machine learning lifecycle from data preparation to deployment and monitoring.
With the growing complexity of ML systems, organizations need scalable, modular platforms that can automate workflows, enforce version control, and enable continuous integration and delivery. Many of these tools align with DevOps automation examples, allowing ML teams to adopt proven automation practices from traditional software engineering.
Whether you’re building models on-premises or in the cloud, the right toolset can make the difference between experimentation and production-ready success. Below is a curated list of widely adopted MLOps tools and frameworks that help teams move faster, collaborate better, and deploy smarter.
1. Experiment Tracking: MLflow, Weights & Biases
- MLflow provides comprehensive experiment tracking, model registry, and deployment capabilities. Teams use MLflow to track parameters, metrics, and artifacts across experiments.
- Weights & Biases offers advanced experiment tracking with collaborative features. It excels at hyperparameter optimization and model comparison.
2. Pipeline Orchestration: Airflow, Kubeflow
- Apache Airflow handles complex workflow orchestration with robust scheduling and monitoring. It’s ideal for batch processing and ETL pipelines.
- Kubeflow specializes in orchestrating ML workflows on Kubernetes. It provides native support for distributed training and deployment.
3. Deployment & Serving: Seldon, TensorFlow Serving, SageMaker
- Seldon Core enables advanced deployment strategies, such as A/B testing and canary deployments. It supports multiple ML frameworks and languages.
- TensorFlow Serving optimizes model serving for TensorFlow models. It provides high-performance inference with built-in versioning.
- Amazon SageMaker provides end-to-end MLOps capabilities, featuring integrated tools for training, deployment, and monitoring.
4. Monitoring: Arize, Fiddler, Evidently
- Arize offers comprehensive model monitoring, including drift detection and explainability features. It helps teams understand model behavior in production.
- Fiddler focuses on model performance monitoring and explainability. It’s particularly strong for regulated industries requiring model transparency.
- Evidently offers open-source monitoring with a focus on detecting data and model drift. It provides detailed reports and visualizations.
Organizations like Folio3 Managed Cloud Solutions use these tools to build comprehensive MLOps platforms. Their managed services, often integrated with DevOps consulting, help companies implement best practices for MLOps without requiring them to build internal expertise from scratch.
FAQs
What is MLOps, and why is it important?
MLOps (Machine Learning Operations) combines ML system development with operations principles. It’s important because it bridges the gap between model development and production deployment, ensuring the reliability and scalability of ML systems.
How is MLOps different from DevOps?
While DevOps focuses on software development and deployment, MLOps addresses unique ML challenges like data versioning, model training, and drift detection. MLOps extends DevOps principles to handle the complexities of machine learning workflows.
What are the key components of an MLOps pipeline?
Key components include data ingestion, preprocessing, model training, validation, deployment, and monitoring. Each component requires specialized tools and practices to ensure reliability and scalability.
Why is model monitoring essential in MLOps?
Model monitoring detects performance degradation, data drift, and system issues before they impact business operations. Without proper tracking, models can fail silently, resulting in poor decisions and lost revenue.
Conclusion
Implementing MLOps best practices transforms experimental models into production-ready systems that deliver consistent business value. The eight practices outlined in this guide provide a roadmap for establishing reliable and scalable ML operations.
Remember, MLOps isn’t just about tools, but it’s about creating alignment between people, processes, and platforms. By starting small and iterating quickly, teams can gradually increase their MLOps maturity, driving better outcomes across the board.If you’re ready to move beyond experimentation and scale your machine learning systems efficiently, Folio3 Cloud Solutions can help. Our expert teams specialize in building, managing, and optimizing MLOps pipelines tailored to your business needs, allowing you to focus on creating value rather than just maintaining infrastructure. Reach out to learn how we can support your end-to-end ML lifecycle.











